via Latent-Space Collocation
The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities.
Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize.
To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models.
The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals.
Latent Trajectory Optimization
Latent collocation (LatCo) on a tool use task, where the thermos needs to be pushed with the stick. Each image shows a full plan at that optimization step, visualized via a diagnostic network. LatCo optimizes a latent state sequence and is able to temporarily violate the dynamics during planning, such as the stick flying in the air without an apparent cause. This allows it to rapidly discover the high-reward regions, while the subsequent refinement of the planned trajectory focuses on feasibly achieving it. In contrast, shooting optimizes an action sequence directly and is unable to discover picking the stick as the actions that lead to that are unlikely to be sampled.
More LatCo Examples
Overview of the Algorithm
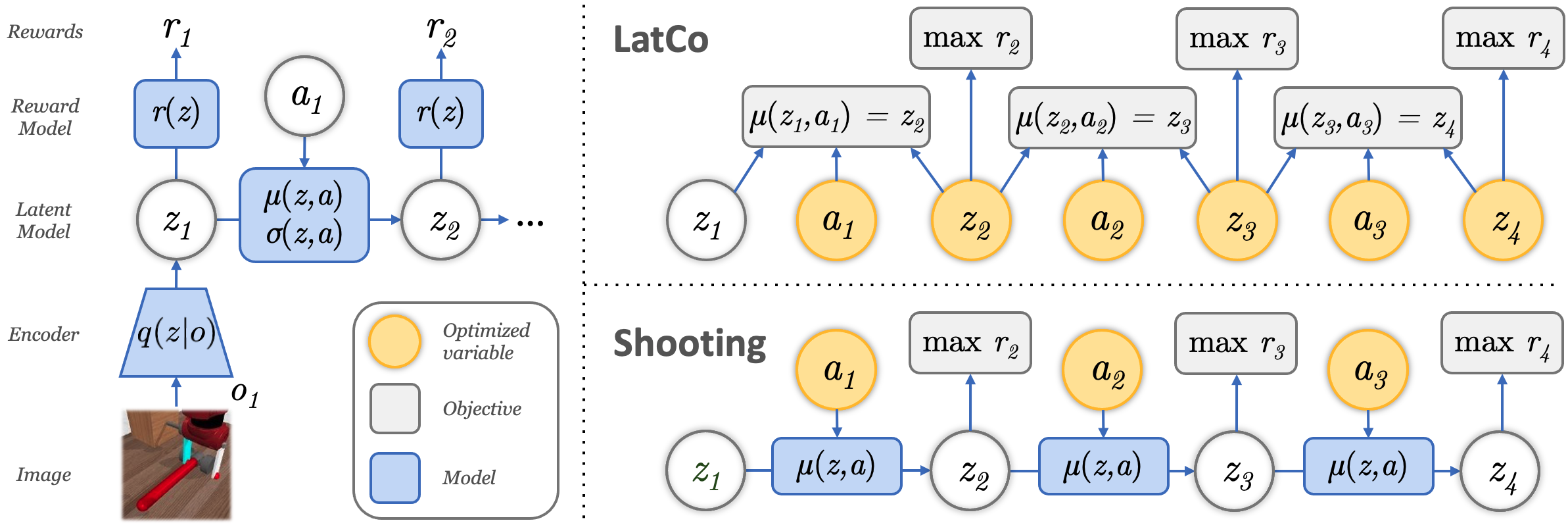
We propose a visual model-based reinforcement method that optimizes sequences of latent states using a constrained optimization objective. First, a latent dynamics model is learned from images using an approximate maximum likelihood objective (left). While shooting (bottom) optimizes actions directly, LatCo (top) instead optimizes a sequence of latent states to maximize the reward. The latent states are constrained to be dynamically feasible by recovering the corresponding sequence of actions and enforcing the dynamics. Dual descent on the Lagrangian is used to solve the constrained optimization problem.
LatCo Results
Our method performs these seven challenging sparse reward and long-horizon tasks directly from image input. While prior work on model-based reinforcement learning struggles with long-horizon tasks, latent collocation (LatCo) plans sequences of latent states using a constrained optimization objective, which enables is to escape local minima and make effective visual plans even for complex multiple-stage tasks like Thermos and Hammer.
Comparisons - Hammer
Comparisons - Thermos
The Thermos and Hammer tasks require picking up a tool and using it to manipulate another object. The sparse reward is only given after completing the full task, and the planner needs to infer all stages required to solve the task. While LatCo can solve both of these challenging tasks, prior shooting methods fail to find a good trajectory.
Source Code
Try our implementation of LatCo in TensorFlow 2 as well as the Sparse MetaWorld environment below!

|
Citation |
|
@misc{rybkin2020model,
title={Model-Based Reinforcement Learning
via Latent-Space Collocation},
author={Rybkin, Oleh and Zhu, Chuning and
Nagabandi, Anusha and Daniilidis, Kostas
and Mordatch, Igor and Levine, Sergey},
booktitle={International Conference on
Machine Learning (ICML)},
year={2021}
}
|